A framework for ignite¶
This guideline is written for ignite contributors interested in further enhancing and expanding the PyTorch Ignite feature, usability and broadening the user spectrum. In the following a concept of a rapid-feature-development framework is suggested underlying the current Ignite concept. It is meant to provide the full infrastructural code layer on which feature can quickly evolve. It should help to overcome possible limitations of the current Ignite architecture. For full understanding of this guideline a base knowledge of the current Ignite architecture is very helpful as the text will compare the new framework with the current version.
The guideline is kept short & simple and serves the only purpose to quickly give other contributors an overview of the current version’s shortcomings and arising advantages of the framework. It basically consists of this page, the Quickunderstanding Application and the Quickunderstanding Feature Dev. All statement made here are just based on my own impressions & analysis and I’m open for discussion & feedback of any kind, THX!
If you just want to checkout the features of the framework, skip the following sections and proceed with a Quickunderstanding Application.
Motivation¶
This framework concept for PyTorch Ignite aims to enhance the current high-level training application to a rapid feature prototyping framework that serves the full user spectrum, not only application developers but also researchers & engineers and the feature developer who are enhancing Ignite itself. To be successful on the long term, I believe it is necessary to serve the full spectrum of users, especially the researchers to end up in high quality application APIs.
The personal motivation arose when I tried to implement some new features and efficient APIs and reached restrictions within the architecture and provided infrastructure. Additionally, I was lacking a certain overview of the training processes I just had implemented when debugging.
Two issues¶
I am a fan of Ignite and that’s why I’m trying to contribute, but I discovered 2 shortcomings in the architecture and the implementation, that caused me quite some restrictions and coding infrastructure instead of programming new features (what I actually wanted to do). The issues are:
- Engine centered architecture: In current Ignite the Engine is the architectural center with the training state as attribute. The training state atttribute is a transient object that is only instantiated when the Engine is in run-mode and vanishes afterwards. Also the state holds only a selective fraction of all variables and parameters that make up the real training state. So Engine is a kind of static object and state is transient. This does not represent the reality of the training process. In reality the training starts with an initial state holding all variables, parameters including e.g. model variables, hyperparameters etc. which then are modified while the state goes through different transitions. The main transitions of the state are Engines (normally more than one). So the state should be the architectual center holding ALL variables, parameters, values, transitions etc. and the Engine is (just) the main trainsition of the state. This small twist causes quite some complications for features and APIs which are listed below.
- Event is broken in many pieces: Currently an Event is an Enum that has to be explicitly fire_evented, and implicitly _fire_evented so the event_handlers handle further callbacks. The Event is always fired after some other training value has changed, e.g. the model output was updated ITERATION_COMPLETED is fired. Also if you want to fire a non-standard event, you first have to create it, register it at each Engine that is supposed to use it and then the firing has to be implemented… But in reality an Event is nothing more than a value change of a training state variable that triggers callbacks. So all these pieces above can be put together by implementing a state variable as a descriptor.
Resulting Ignite limitations¶
Even though Ignite is a perfect, zero-boilerplate tool for standard applications I experienced limitations when working with more complex use cases, e.g. multiple engines (up to 3 very common) with customized events and metrics being compared in shared charts etc.. Again these are just experiences I have made (you may disagree).
Have a look on the “current” Ignite architecture overview for better understanding of the following limitations. (Please excuse if it may be slightly outdated/altered, but the base structure should still be representative.)
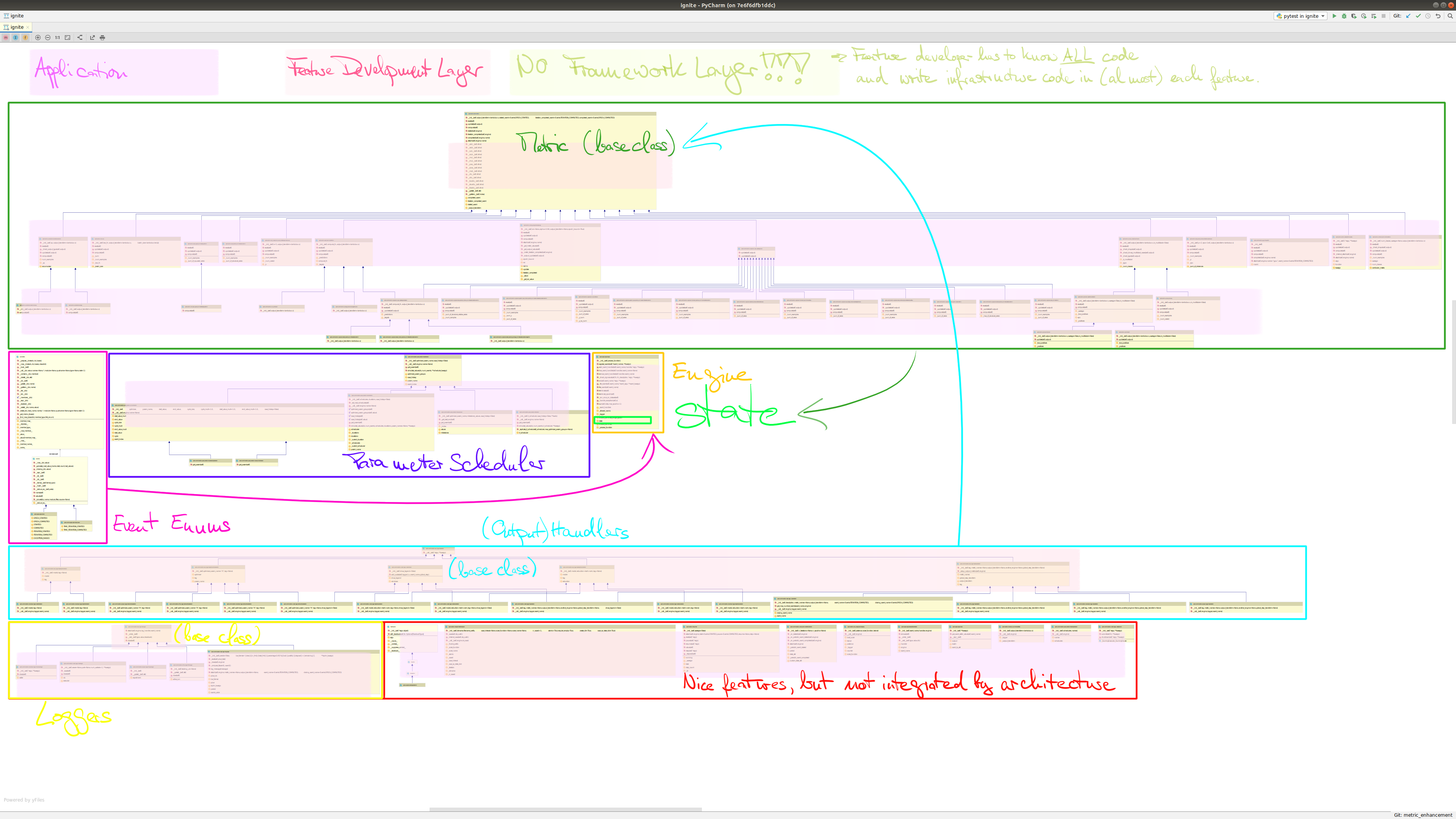
On the application level:
- Event-system:
- complicated with many commands
- new Event musst be register for each Engine separatly
- global Events would have to be fired in all Engines separately
- no overview over all existing Events
- only very view default Events implemented (currently 9?)
- for non-standardized use cases boilerplate code strongly increased
- every non-standard Event causes high boilerplate code amount (despite the nice every/once solution)
- charts are restricted in number of engines & x-axis choice
- no overview during debugging, state only exists when Engine is running
- for simple debugging of your application you need approx. 60% knowledge of the current Ignite code to understand how an Event works, where the callbacks are & when i can find them (vanishing state)
- no analysis tools provided for the application, e.g. data flow graph or time sequential analysis, which may be impossible to implement in current architecture
On feature development level:
- restrictive architecture:
- If you’re honest, the architecture is laid out for a single engine: any current extensions for 2 engines (another engine) are breakouts from the current restrictive architecture and end with
another_engine… for 3 engines one would really needa_third_engine. - Only
Enginecan hold and fireEvents and store variables (inEngine’sstate) which can be properly reference by other features (referencing is done by passing the complete engine to the feature). This strongly restricts all other features in their possibilities. - As seen in the class diagram, the architecture is restricted to one type of
Engine, toMetrics, andOutputHandlers. The other provided features (red box “Nice Features”, e.g.EarlyStopping,TerminateOnNan) are not integrated by the architecture.
- If you’re honest, the architecture is laid out for a single engine: any current extensions for 2 engines (another engine) are breakouts from the current restrictive architecture and end with
- The framework abstraction layer is missing, feature and infrastructure code are entangled:
- feature development requires full knowledge of code (only new metrics are rapidly implemented with Metric)
- new features very often require new infrastructure code to get the variables you need, especially if they’re located on different engines
- no clear design rules for new features (despite for
Metric) implying risk of architecture degradation - no global state values/objects providing system: the distribution of variables on different engines and vanishing variables of state forced me into a lot of boilerplate code or even made me brake the architecture ending in a hack
On the infrastructure level:
- no separation of infrastructure and feature code
- developing new features always requires coding infrastructure to get the required objects (e.g. model output of different engines) into the feature
- almost no inheritance structure which leads to redundant code in different classes as each is a superclass on each own
- lacking inheritance structure also implies higher risk of update abnormalities and hinders fast or major infrastructure changes
Improvements from an underlying framework¶
You will experience the improvements given by the framework when working on all 3 levels: application implementation, feature development and framework development. The separation of these working areas is already the first improvement. Try out the benifits in detail & hands-on for the first to levels in the Quickunderstanding Application and Quickunderstanding Feature Dev.
Before you go through the theoretically described enhancements these few no-comment-teasers of the training state in the debugger will give you nice insights what’s ahead. It shows the Ignite example mnist_with_tensorboard.py transferred to the framework architecture just before the engines are started:
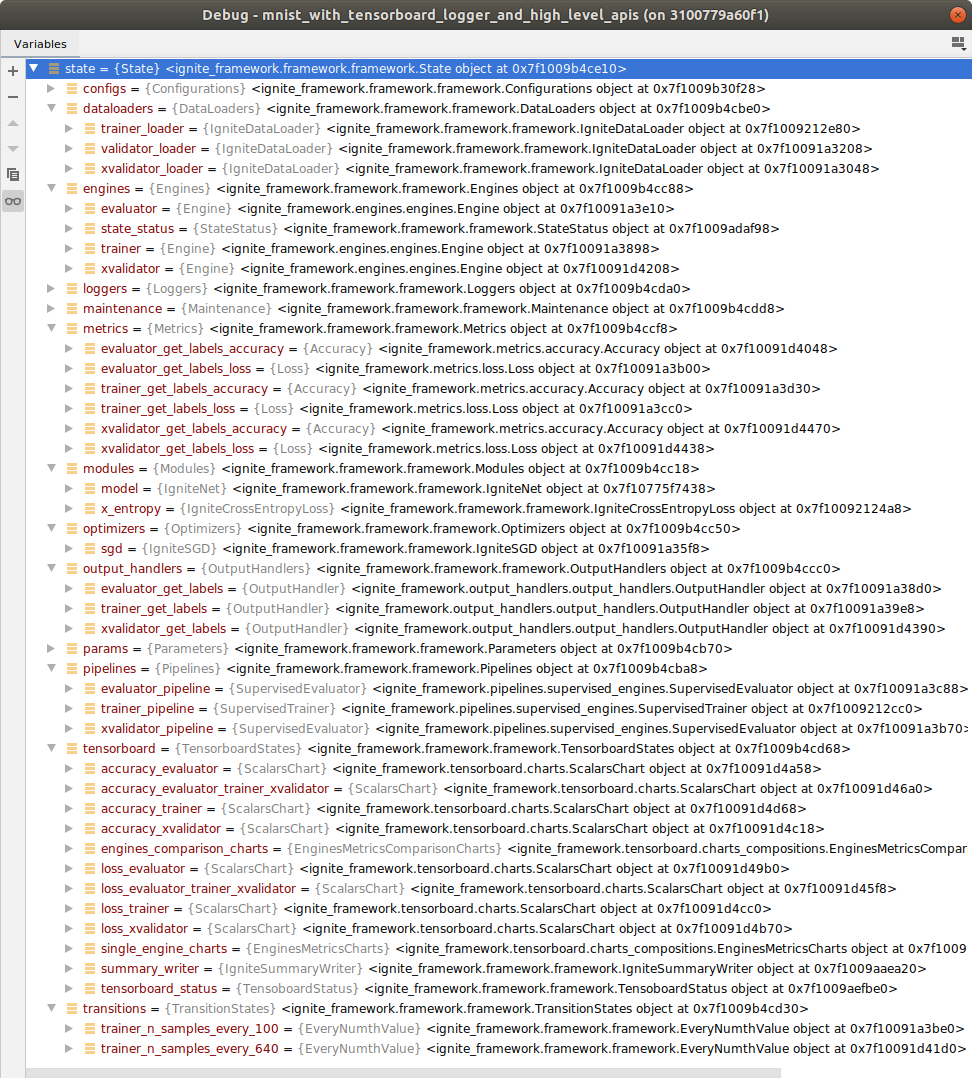
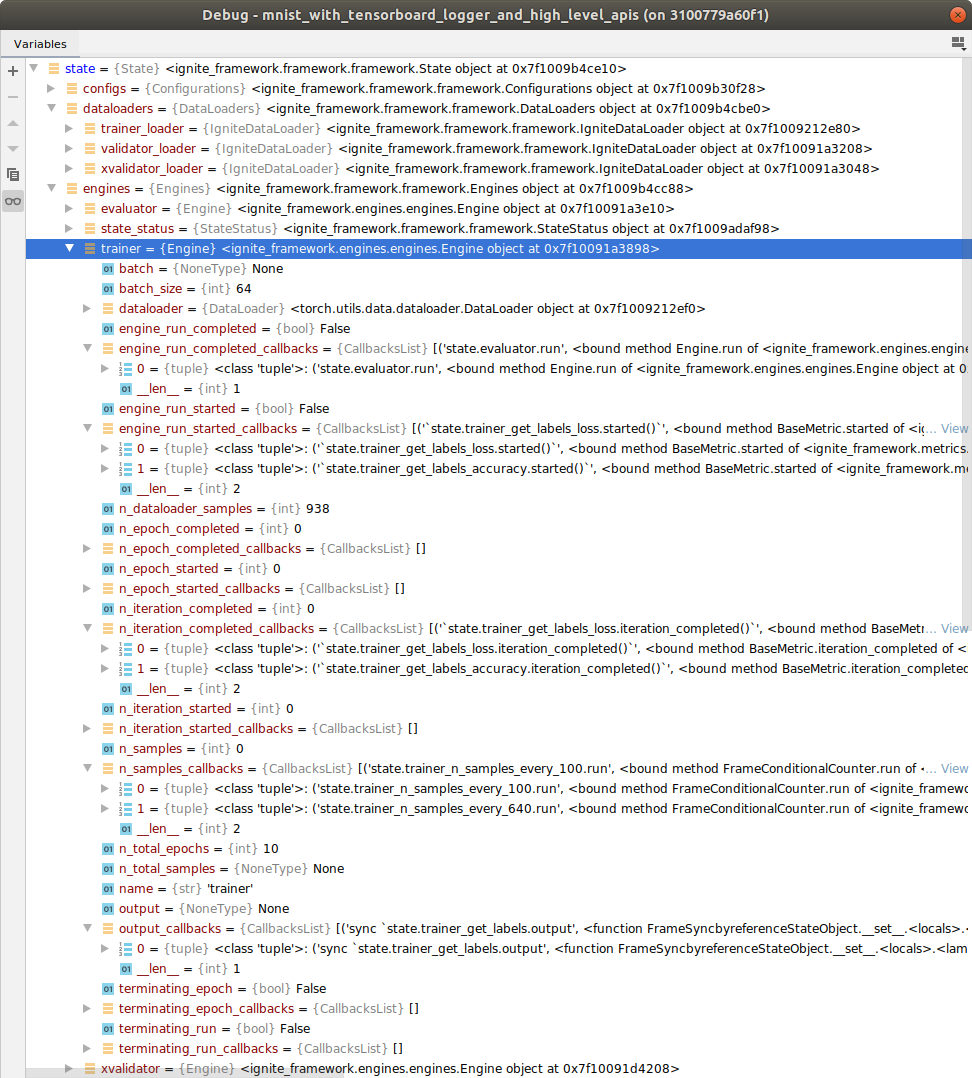
And here the engine state.engines.trainer unfolded:
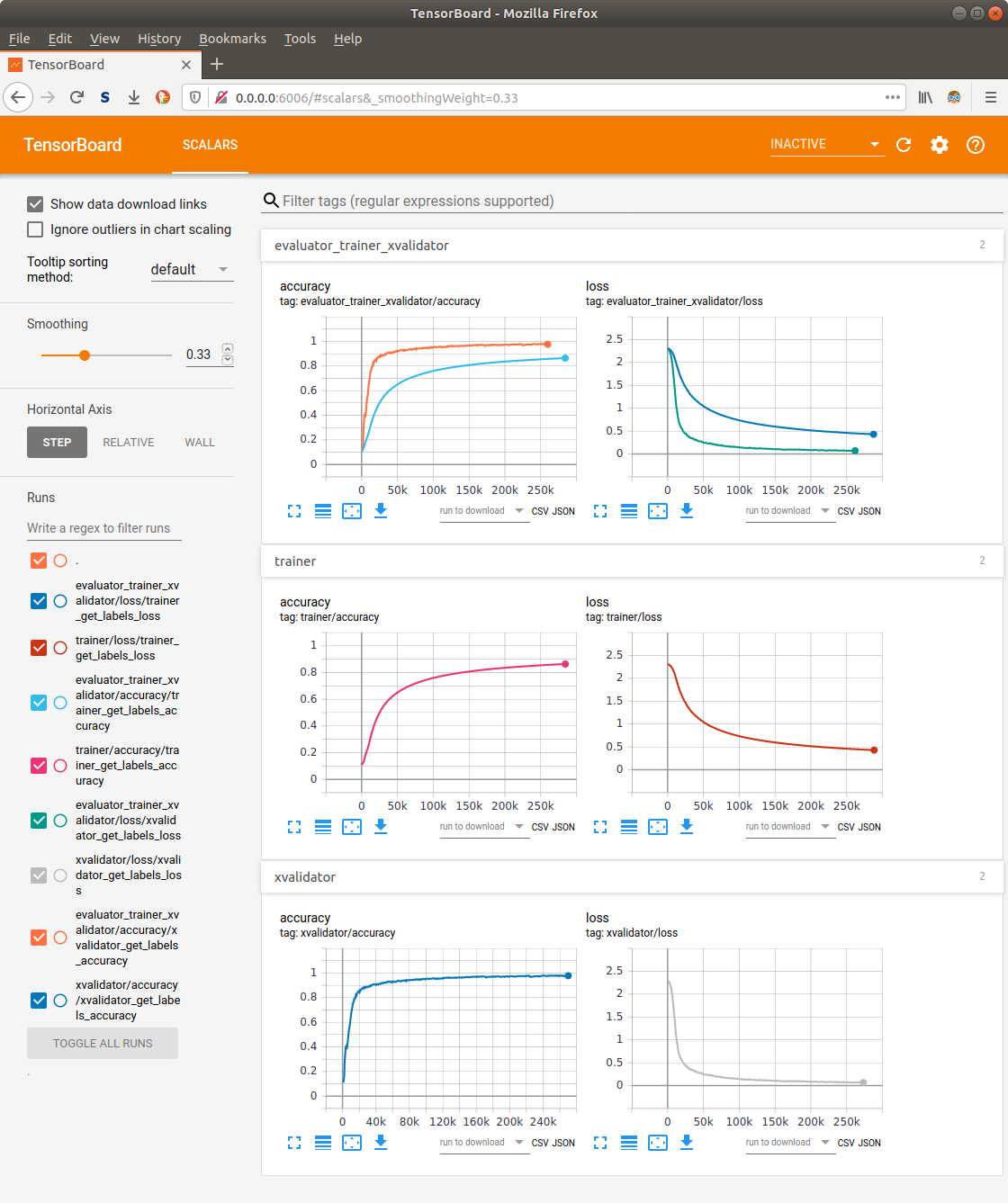
Or setting up all the below Tensorboard charts with these two simple comands:
# Automatically identify and generate metric chats comparing the different engines
EnginesMetricsComparisonCharts(x_axis_ref=state.trainer.n_samples_ref, n_identical_metric_name_suffixes=1)
# Automatically generate for each engine a summary of all metric charts
EnginesMetricsCharts(x_axes_refs=state.trainer.n_samples_ref, n_identical_metric_name_suffixes=1)
By the way, if you had set up 10x more metrics and some more engines, these two command would not change to provide all comparative and single metric charts of all engines.
The framework development is not yet documented. For the moment, I can tell you this: While in the current Ignite architecture I found it challenging to find out how & where I could possibly add a little syntactic sugar, in contrast the challenge with the framework is rather cherry picking, trying to keep the syntax pythonic and not putting in too much magic (I hope I didn’t already!). This also remains the ongoing challenge of the future framework programming to adjust the syntax to optimal workflow.
Have a look at the framework scheme showing all main components of the framework.
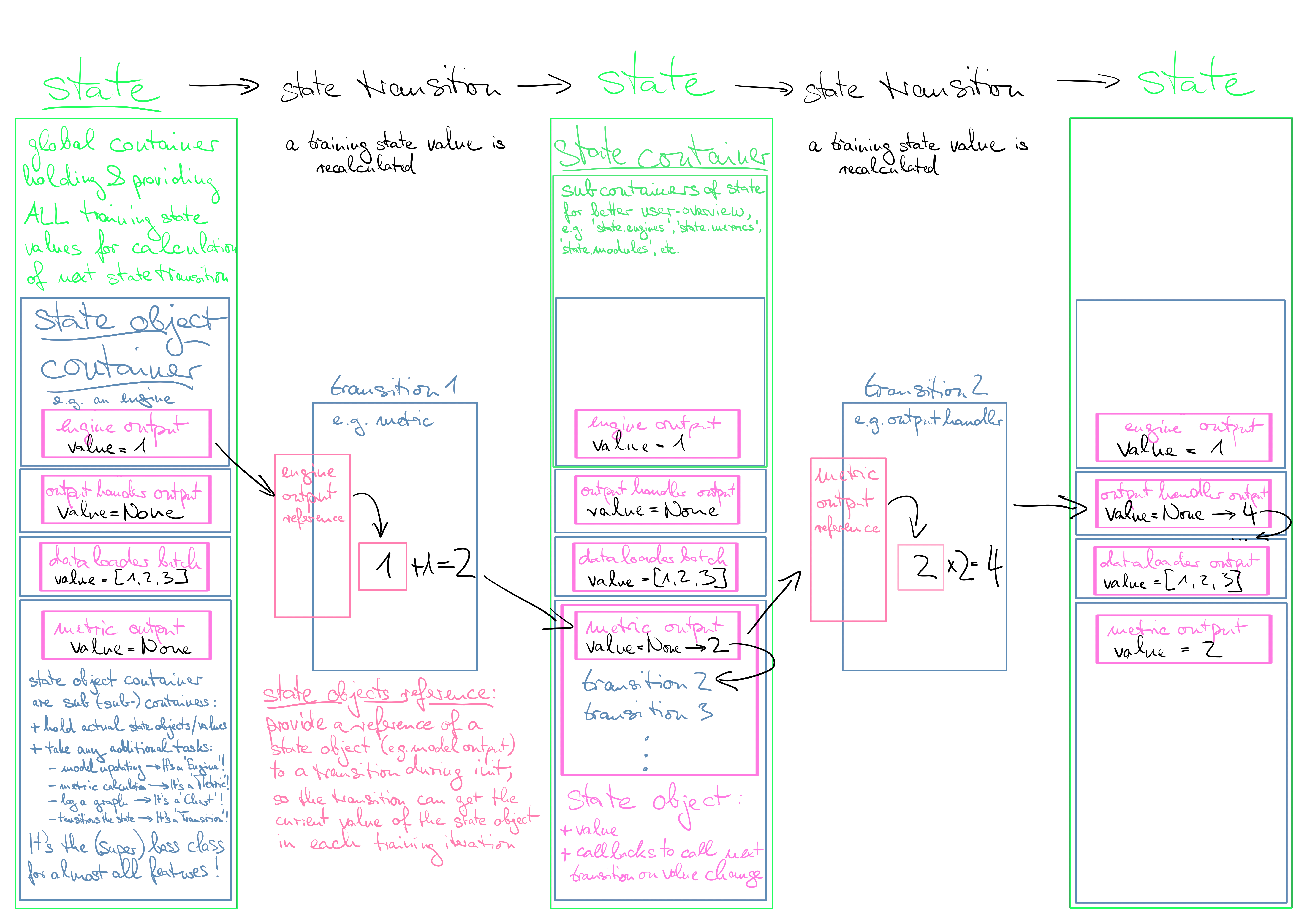
The framework provides 5 basic components (& of course some subclasses):
- state: a global container providing all state objects/values/variables/parameters etc. to any feature.
- state comtainer: sub containers of state to categorize similar features together, e.g. engines, metrics, optimiziers, etc.
- state object container: the final sub container which hold the actual state objects/values and is the base class for all features. This base class (to be 110% precise, the supertypeclass MetaFrameStateObjectContainer) has by default all functionalities integrated which currently only
Engineprovides, i.e. holding referencable state values, a fully blown event system (incl. firing, event_handlers, attaching etc.) and even more. This is why the defaultEnginein the framework is also just another feature derived from the state object container (see framework architecture diagram below). - state object: finally the state object is the actual state value (e.g. engine output) and full event system all-in-one. It attaches to the state object container as class bound descriptor (class attribute) and comes with an additional callback list, which holds the callables that are called each time the value of the state object is set. The state object descriptor is the pendant to the current complete Event system of Ignite and setting the state object value is the pendant to firing an event.
- state objects reference: a integrated referencing object enabling the data flow between the state object containers. It creates a reference object of state objects which are handed into a state object container at initialization to provide update values of the state objects during training iterations.
Of course many subclasses of these basic components already exist & there are far more to come.
Have a look a the new framework architecture below and compare it with the current Ignite architecture above.
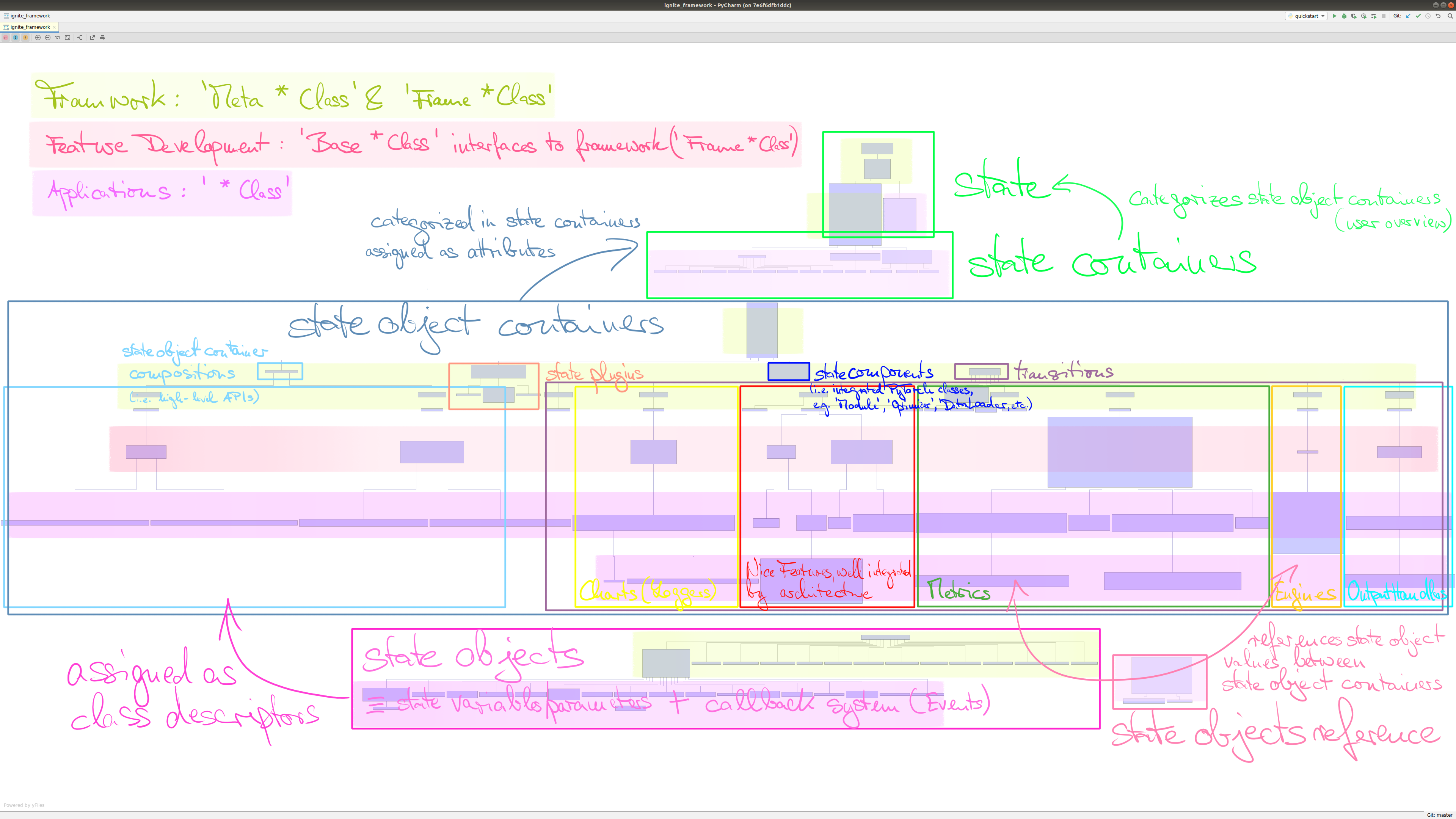
Described in a general sense:
The framework is a low-level code layer running under the hood providing feature developers with any kind of training objects, data, outputs, syntactic sugar, analysis tools (and visualizations soon), extendable plugins, and so on… anywhere, anytime and especially with the need of zero code knowledge to use it. The required user knowledge is reduced to basic design rules and features which the framework provides mainly as Base*-classes and from which on she/he starts coding. The framework itself runs mainly on Meta*- and so-called Frame*-classes.
In more details, the main characteritics of the framework architecture are:
- state is the architectural center
- state object is an all-in-one state value + event system provided in one piece to the feature developer
- every feature is equipped with referencable state objects, i.e. a full event system… so
Engineis just another feature. - clear inheritance structure of metaclasses and classes for easy major updates and low risk of update abnormalities
- strict separation of framework code layer and feature development code: framework runs on
Meta*-classes &Frame*-classes and the interface from framework to feature development is defined byBases*-classes. No framework code knowledge is required for feature development. - framework code is based strongly on metaclasses & dunder methods providing additional flexibility
- every feature is fully integrated into the architecture
- even external PyTorch class instances are fully integrated as state components by exposing user defined variables & parameters of the instance as state objects to the framework
- next to training features, state also offers configuration, maintenance & analysis features/plugins to increase workflow efficiency
If you’re still interested after this rough summary, you may now proceed with the Quickunderstanding Application
How to integrate the new framework¶
After identifying the two issues I tried of course to fix them within the existing code base. But after having a look at the new framework you probably will agree that this would not have been possible. Therefore, integrating the framework means making code adjustments to every feature class. Still all concepts of Ignite were picked up and integrated into the framework so only the code related to the infrastructure has to changed (simplified), basically the concepts of all existing features remain. You may realize 100% identical code blocks of current Ignite feature in already transferred/frameworked features.
Because of above reasons, before daring to suggest a major change, I went a long way on my own to provide you with a fully up & running framework with all basic features already implemented, so you can start playing with it straight away & make up your opinion based on facts.
Just in case enough contributers are interest in this concept, I could provide the full code and pull-request it on an experimental repository branch.
For an overview on the current implementation status, see below.
Current implementation status of the framework¶
At the moment, I would approximate that 95% of the default framework and APIs are already implemented. However, this estimation excludes parallel & distributed computing features and performance optimization, which would be the next big step to eliminate any GIL-like show stopper risks. The basic framework is up & running. Any further transfer of existing Ignite features to the framework should probably be done after a full discussion about this version of the framework API.
Further I would except the framework code changes to diminish quickly as the syntax and infrastructure will reach their optimum soon. But, thanks to the new architecture tons of new analysis tools, visualization tools and features seem obvious to be implemented now, so I would expect a rapid increase of new developments on the state plugins and feature side.
In bullet points you will currently find already implemented features & classes i.e.:
- all base features of current Ignite, e.g. all event handling functions, every/once-filters, engines, metrics, output handlers, charts, summary writer…
- additional features demonstrated in Quickunderstanding Applications, Quickunderstanding Feature Dev and the other example scripts
Base*-classes for all categories (, e.g.BaseMetric,BaseOutputHandler,BaseEngine,BaseChart,…)- application classes, e.g.
Engine,OutputHandler,Accuracy,Loss,AverageOutput - high-level application classes/pipelines, e.g.
SupervisedTrainer/Evaluator(roughly),EnginesMetricsCharts,EnginesMetricsComparisonCharts
Missing implementations:
- distributed & parallel computing
- concept for automated output handling
Sorry for…¶
…currently not providing you with a real documentation and references and no tests so far. At the moment the Quickunderstanding Application, the Quickunderstanding Feature Dev and the Examples may be the best way to get started. I may provide further documentation on demand and will proceed depending on the feedback…
Content¶
Documentation
Warning
GIBBERISH PATCHY & DEPRECIATED REFERENCES AHEAD
Take nothing for granted… to be updated.
Features & Devs References
