Quickunderstanding Applications¶
This hands-on demonstration introduces most application features of the framework in a logical order for best comprehension. The order absolutely differs from an application script feature order and therefore will not end in a useful ready-to-use training script, but rather a rubbish script. Ready-to-use application scripts are provided in Examples. I recommend to start with the mnist training script with low level APIs (low-level-API a.k.a. feature or transition or base state object (bso) container, see definition below) because it’s a known example from Ignite transferred to the framework and implemented with low-level features. Next compare it with the same mnist training but using high level APIs, a.k.a. pipelines and state object container compositions (also described below). You may inspected these scripts in parallel to decide which suites your comprehension best.
So what is the framework all about? To answer this question clone the repository in your Ignite environment and run quickunderstanding_app.py in debugger mode. Step over the first line… oh, but before that… grab a coffee & relax:
from ignite_framework.states import state
Check out state in your debugger variable window:
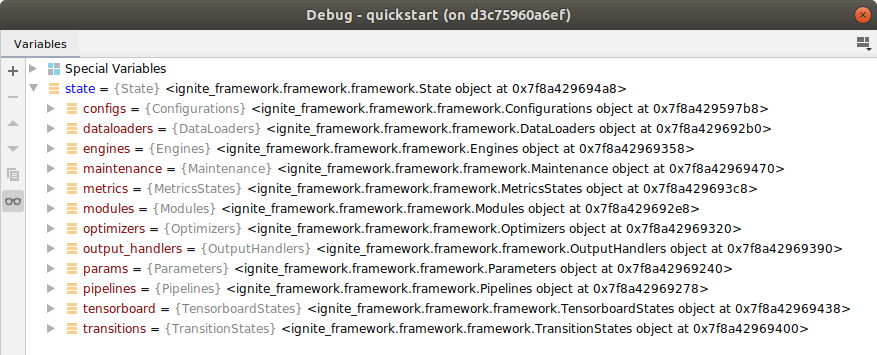
The state represents the complete training state including all variables, parameters, PyTorch components (e.g. models/modules, dataloaders, summary writer). It provides the users with maximum overview over the current training state by (automatically) categorizing its values and objects into state containers (e.g. state.dataloaders, state.engines, etc.) and automatically runs all kinds of infrastructure tasks in the background. As this framework is a rapid feature development tool, here the user not only includes the standard application developer but already the feature developer as well as researchers and engineers working on complex use cases and experiments.
State -> State Container -> State Object Container -> State Object¶
Now let’s get an idea about the functionalities all included in the main component state. Step ahead and add an engine with a simple process method to state:
from ignite_framework.engines import Engine
def average_batch(engine):
return engine.batch / len(engine.batch)
Engine(name='trainer', process=average_batch, dataloader=None)
This looks simple, possibly a bit strange because you did not assign Engine to any variable. Have a look at your debugger variables:
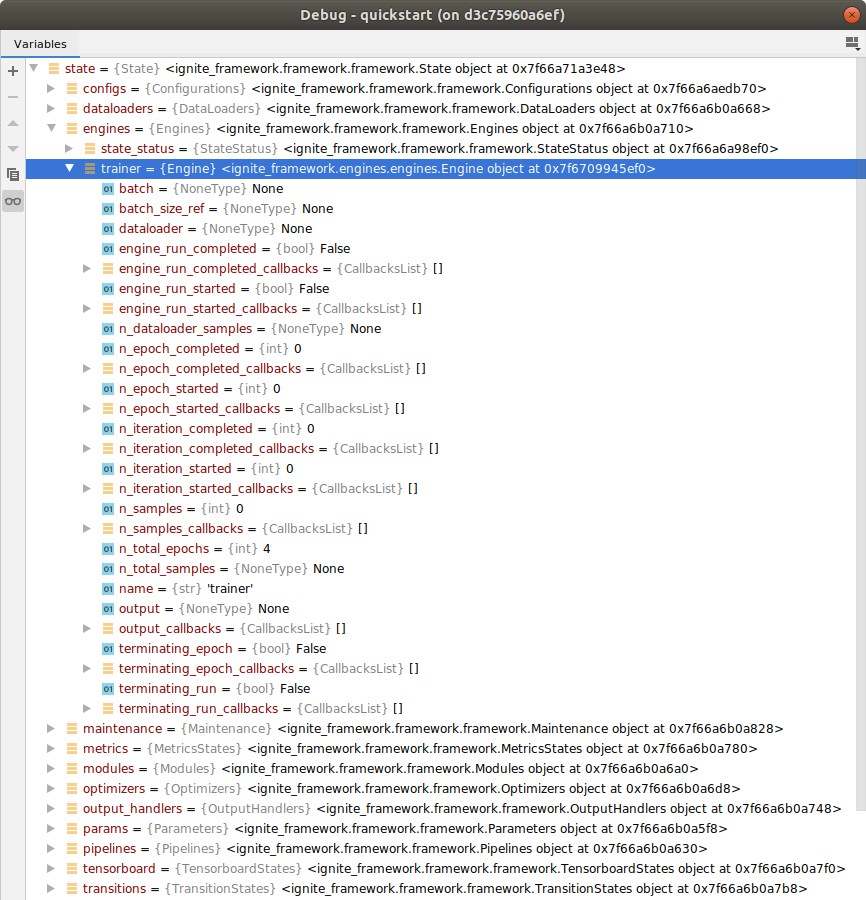
The following happend and was created:
stateautomatically categorized the newtraineras anEngineand assigned it to the appropriate (so-called) state containerstate.engines. The same assignment occurs when creating new metrics (state.metrics), output handlers (state.output_handlers) or charts for the metrics (state.tensorboard). This gives the user great overview, takes over variable handling for the user and reduces code.- Within the
trainer: - you find that no dataloader was defined yet (correct!)
- and
trainerhas many familiar looking variables liken_epoch_started,n_iteration_startedetc.. But to most of those familiar variables you will also find a new variable*_callbacks. Any of these variables with additional callback variables are state objects, also called base state object (bso), the pendant to the current event system implementation and a central object of the framework infrastructure. The name comes from their superclassBaseStateObject. The enginetrainercontaining the state objects is also called a state object container, or base state object container (bso-ctr) derived from its supertypeclass nameMetaStateContainer. The state object containers are often referred to as transitions because many of them transform the state (values) with their methods (e.g.trainer.process()). And sometimes they may be described as features, e.g. when talking about this framework being designed for rapid feature development. No worries, that’s it regarding weird namings and their abbreviations!
- Within the
Note
Naming base state object vs. state object
Different subclasses of base state objects exist, e.g. StateVariable, StateParameter, StateDevice, etc. and the most simple one StateObject, all inheriting from BaseStateObject. So the correct umbrella term for sure is base state object. But as this may be unhandy the shortened term state object can be used. Be aware the name state object can become ambiguous when discussion explicitly the BaseStateObject classes w.r.t. StateObject, but in general discussions it is uncritical. Also don’t confuse it with a general object in the state.
Next, the base state objects require some attention to understand all advantages.
We will use the shortcut feature of state in the next section to shorten the longish state object getter & setter expressions:
>>> state.engines.trainer.n_epoch_started
0
>>> state.trainer.n_epoch_started
0
>>> state.n_epoch_started
0
>>> id(state.engines.trainer.n_epoch_started) == id(state.n_epoch_started)
True
Base State Objects (short: State Objects or bso’s)¶
Variable/Parameter with callback feature¶
Base state objects (bso’s) or short state objects are state variables/parameters (e.g. model output) and the event system all-in-one. They are implemented as class bound data-descriptor (and non-data descriptor, e.g. StateConstant), so many functions can be embedded and they are simply set up as regular class attribute (see Quickunderstanding Feature Dev). Expressed in Ignite terms, each time the value of a state object is set, it fires (itself being) the event and triggers the callables stored in its event_handlers, a.k.a. callbacks. As the framework needs no event flags or event firing, you simple say the state object triggers/calls its callbacks when its value is set. So lets go through the simple steps of attaching a callable to a state object and (firing the event by) setting the state object value to trigger the callbacks.
# Define a callable
def print_triggered():
print('`state.n_epoch_started` was triggered!')
# Attach callable to bso with overload feature detecting the value type
state.n_epoch_started = print_triggered
Value type overloading¶
I could not think of anything simpler than attaching with =. So the state object is overlaoded, it detects the value type and understands if you’re setting the value or attaching a callable to the callbacks. State object also automatically includes automated descriptions of the callable and it’s (empty) arguments:

Alternatively one could use a decorator during function definition:
# Define and attach with decorator
@state.n_epoch_started_callbacks.append
def print_another_trigger():
print('`state.n_epoch_started` has another callback now!')
But the auto-description cannot be provided in this case as you see in the debugger screen shot above. Now let’s trigger the callbacks by increasing the epoch counter:
>>> state.n_epoch_started += 1
`state.n_epoch_started` was triggered!
`state.n_epoch_started` has another callback now!
As you normally have a lot of state objects in a state you get by default tons of very individual ‘events’ which in current Ignite have to be coded with the known procedure.
Note
tuples for appending callbacks
tuples are also understood as callbacks but only with very restrictive content conditions as many model outputs are also provided as tuple. The tuple must either have the exact length and element types of the appended tuple in the callbacks list or be a sublist of it without changing order and the callable/bso must be included in any case.
Name suffix overloading¶
State object names can be called with (up to 3) _-separated suffixes that call different features. These suffixes will be demonstrated below and are:
_every/once,every/once_<int>: pendent to event filter_ref: returns a reference of the state object_callbacks: which is not really a suffix overload because the variable exists, but in case of multiple suffixes it is
_once/_every suffix overloading¶
def print_triggered_every_2():
print('`state.n_epoch_completed_every_2` was triggered!')
# Once/Every suffix-overload function
state.n_epoch_completed_every_2 = print_triggered_every_2
# Alternative for just creating a customized callback
state.n_epoch_started_once = 42
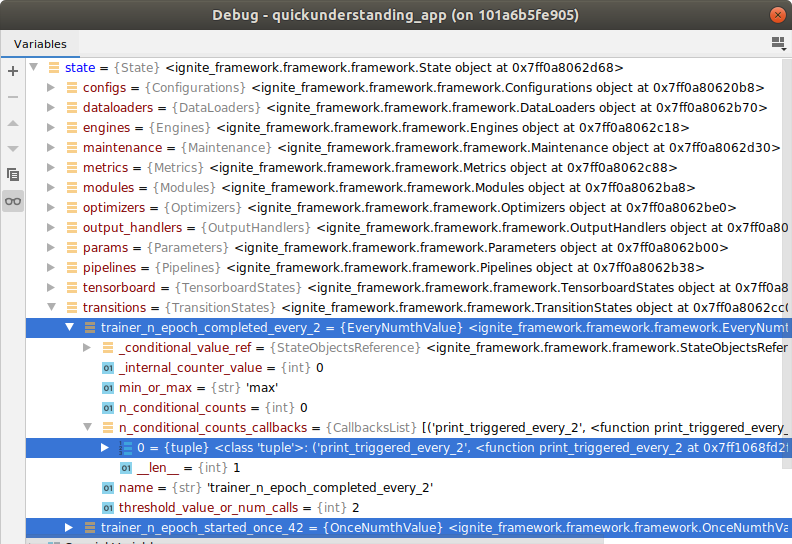
What just happened? Two things:
- Two new transition (bso containers) namely
trainer_n_epoch_completed_every_2(EveryNumthValue) andtrainer_n_epoch_completed_once_42(OnceNumthValue) were created instate.transitions, the state container for general state transitions. - The
print_triggeredfunction was added to the callbacks of the conditional counterstate.trainer_n_epoch_completed_every_2.n_conditional_counts_callbacks
This is an example for the limitations of the current Ignite compared to the framework. The current Ignite architecture forced to introduce a filter, another extension of the architecture (actually a complete re-implementation of Events making them callable) to break out of its shortcomings. And it’s quite a job to fit such features into those boundary conditions. Anyway, it required some lines of code to implement the suffix overloading, but the framework architecture stayed unchanged.
>>> for n in range(10):
... print(n)
... state.n_epoch_completed += 1
0
1
`state.n_epoch_completed_every_2` was triggered!
2
3
`state.n_epoch_completed_every_2` was triggered!
4
5
`state.n_epoch_completed_every_2` was triggered!
6
7
`state.n_epoch_completed_every_2` was triggered!
8
9
`state.n_epoch_completed_every_2` was triggered!
_ref suffix overloading¶
As described here references are required to define the bso container inputs coming from preceding bso containers during initialization but getting updated values during training iterations. In the current Ignite the only way values are referenced is by handing in the complete engine, including its state, e.g. to a metric. This is not a very precise reference, so the framework enhances this process by enabling single state object referencing based on the StateObjectsReference class and the suffix overload _ref:
## REFERENCE ##
# Create a reference object
n_epoch_started_ref = state.n_epoch_started_ref
# The reference object has the default `caller_name` caller name that substitutes `n_epoch_started`
# Equivalent: `state.n_epoch_started`
print(n_epoch_started_ref.caller_name)
# Equivalent: `state.n_epoch_started_callbacks`
print(n_epoch_started_ref.caller_name_callbacks)
# Equivalent: `state.n_epoch_started = ('attached_with ref', print_triggered)`
n_epoch_started_ref.caller_name = ('attached with ref', print_triggered)
# Equivalent: `state.n_epoch_started += 1`
n_epoch_started_ref.caller_name += 1
Feature initialization with references is very handy, because you can now server 3 argument types with one expresiion:
- data reference
- caller reference (trigger event)
- state object value (current value of state object could be used during initialization, sightly trivial)
When initializing e.g. a OutputHandler and you pass in the input_ref=state.trainer.output_ref argument assigning the output value of your trainer engine, this can be used of course to provide the current output in each iteration. Additionally, in case no explicit caller_ref argument is set, i.e. the state object that calls/trigger the outputhandler to update itself, then as default the input_ref (which also has a callbacks list) will be used als callback/trigger event/caller_ref. This is absolutely not possible in the current Ignite because the event system is broken apart from the state values as descibed in the comparison of current Ignite and this (possible) framework update<Two issues>.
Warning
You WILL forget the suffix _ref in arguments quite often in the beginning
As handy as the _ref suffix is as easy you will forget to add it when initializing a bso container with reference arguments, e.g. an engine with engine_run_started_ref=state.trainer.engine_run_completed (!!!). No worries, the error message look something like:
AttributeError: 'int' object has no attribute 'caller_name'TypeError: `int`/`str` object ...
So just remember & add the _ref.
State object synchronization with _ref suffix¶
It is also of interest to be able to synchronize some state objects, e.g. parameters like
## FSO SYNCHRONIZATION ##
# Synchronize parameters: only in one direction to avoid recursion error
state.n_epoch_started = state.n_epoch_completed_ref
# Change bso 'in sync-direction'
state.n_epoch_completed += 1
# Results in changing value of `state.n_epoch_started` and triggering its callbacks
print(state.n_epoch_started)
# But does not sync in other direction
state.n_epoch_started += 1
print(state.n_epoch_completed)

Note
Be aware that when synchronizing to state objects, also the current value is synchronized which may lead to a FrameworkValueError or FrameworkTypeError, e.g. trying to sync a IterationCounter with current value 0 with another one with current value 5 (allows only iterations steps of +1).
Parametrized State object calls¶
Every/Once callbacks are often parameter dependent (e.g. how often to run evaluation engines) so the according state object must be get/settable with parameters. Actually there is a .get(*name_or_parts), .set(*name_or_parts) for state, for all state containers and state object containers:
### PARAMETTRIZED STATE OBJECT GETTER/SETTER ###
n_every = 2
n_once = 55
filter = 'every'
state_object_name = 'n_epoch_started'
overload_feature = 'callbacks'
# Regular use case
state.trainer.get('n_epoch_started_every', n_every)
# No limits to number of parameters
# NOTE:
# - The `.set()` understands the last argument as value and all preceding arguments as state object name parts to be
# joined to one string with `'_'`
# - This here below creates a new transition `state.transition.trainer_n_epoch_started_once_55`
# and appends the function `print_another_callback`
# to `state.trainer_n_epoch_started_once_55.n_conditional_counts_callbacks`
state.trainer.set('n_epoch_started_once', n_once, print_another_callback)
# Print the callbacks list with `.get()` from `state` and `state.engines` and `state.engines.trainer`
print(state.get('engines').get('trainer').get(state_object_name, filter, n_every, overload_feature))
# Append another function to a callback with parametrized state object name
state.trainer.set(state_object_name, filter, n_once, print_another_callback)
# Print the callbacks (here without parameters, but does not matter how)
print(state.trainer.n_epoch_started_every_55_callbacks)
State object types¶
There are already quite a few different types of state objects depending on their type checking, builtin features, non-data or data descriptor and so on, for examples: StateVariable, StateParameter, IterationCounter, StateConfigurationVariable, StateConstant, StateObject, etc.
For the beginning this are the most important features of the state objects. You will find some more when playing with them.
Next, let’s cover important state properties…
…or first another coffee?
State¶
For basic understanding of state have a look at this description and schemes.
The main task of state is to provide the user all training relevant objects with minimum effort (code) and maximum overview. Important objects and values are stored in bso’s (base state objects or short state objects).The state objects are categorized hierarchically for better overview:
- state containing the…
- state containers, e.g.
state.engines,state.configs,state.modulescontaining the… - state object containers or base state object containers (bso-ctr’s), e.g. the
state.engines.trainer, a dataloaderstate.dataloaders.trainer_dataloader, a metricstate.metrics.trainer_average_lossetc., which finally are containing… - the state objects (bso’s), e.g.
state.engines.trainer.n_iteration_completedorstate.metrics.trainer_average_loss.output.
The state provides a pretty complete set of features for a fully functional framework. Here I would only like to demonstrate the following:
- shortcut features for fast-access of training objects and values
- automatic categorization/containerization of training objects & values for maximum overview (e.g.
Engineinstate.enginesabove) - organizational assistance with parameters, configs and function categorization
- integration of (Ignite-)external class instances, e.g. PyTorch
Modules,DataLoaderby exposing relevent parameters or variables tostateas state object (bso) - state container status callbacks (good default events to append transitions) for each state container, e.g.
state.engines.state_status.state_run_started. - naming assistance preventing users to name objects ambiguously, e.g. instantiating an
EngineandDataLoaderboth named trainer - automated naming of training objects, e.g. giving output handlers reasonable names
- vast amount of default callbacks (default events to attach to) in state container status’
statehides any irrelevant infrastructure objects from the user (~95% of variables, 0% of infrastructure methods yet). This is not directly a feature, but somehow it is… and there’s nothing to do for demonstration.
Shortcuts¶
Despite the nice overview of the hierarchy this may also result in longish bso calling expressions, e.g. state.engines.trainer.n_epoch_started. To avoid this, state offers a shortcut feature updating the set of provided shortcuts for all unique bso containers & bso names in state. Therefore the following calls all return the same object:
>>> state.engines.trainer.n_epoch_started
0
>>> state.trainer.n_epoch_started
0
>>> state.n_epoch_started
0
We will see below that state object containers must have different names, so you have shortcuts for every state object container (e.g. state.trainer instead of state.engines.trainer). But for state objects, if a bso container with identical state object name(s) is added to state, then state automatically deletes the shortcuts that have become ambiguous. This is something to be aware of when using shortcuts in applications. In feature development, shortcuts for state objects are a bad idea in general (for state object containers it’s uncritical thanks to the naming assistance, see below).
Organizational assistance¶
state can also integrate general training parameters, variables and functions for easy access and user overview, if desired. Therefore state offers state containers and extra state object containers which you may have noticed some already. Others are automatically generated when adding variables or functions. These containers are listed below and their names should be self-explanatory:
state.configscontaining:state.configs.default_configs: included in default statestate.configs.user_defined_configs: automatically added when user adds additional config parametersstate.configs.helpers: automatically added when user adds additional functions (helpers)
state.enginescontaining (additional to the engines):state.engines.hyperparams: automatically added when user adds hyperparametersstate.engines.helpers: automatically added when user adds functions (e.g. engine process functions etc.)
state.maintenancecontaining:state.maintenance.arguments: automatically added when user adds maintainer argumentsstate.maintenance.helpers: automatically added when user adds maintainer (helper) functions
state.paramsis an automatically generated overview of all parameters instate. No matter which bso container in which state container you instantiate, if it has aStateParameterthen this state parameter will be automatically listed instate.params. It is usefull to keep all parameters in sight and handy for setting up hyperparameter tuning. The exact substructure ofstate.paramsis open for discussions. Furhter you can also add user defined parameters and helper functions:state.params.user_defined_params: automatically added when user adds parametersstate.params.helpers: automatically added when user adds functions
All added objects are assigned to approperiate state object types, e.g. parameters to StateParameters, functions to StateFunctions etc.. But how are they assigned. Please have a look at some (very random) examples:
## Organizational assistance ##
with state.configs as c:
c.hardware_config_value = 123
c.n_gpus = 199
@c
def check_all_configs_were_set():
for config_name in state.user_defined_configs.get_bso_names():
print('state.configs.user_defined_configs.{} = {}'.format(config_name, state.get(config_name)))
for helper_func_name in state.configs.helpers.get_bso_names():
print('state.configs.helper.{} is added.'.format(helper_func_name))
state.configs.extra_path = 'this/is/a/extra/path'
state.params.more_user_params = 199
state.configs.user_defined_configs.directly_assigned = 51
state.check_all_configs_were_set()
# All indented values will be attached to `state.engines.hyperparams` as `StateParameter` (if not defined explicitly as different state object)
with state.engines as e:
# Any non-state-oject will be assigned as `StateParameters(initial_value=value)`
e.evaluator_batch_size = 20
e.engine_param = 42
@e
def max_process(engine):
return float(max(engine.batch))
@e
def double_value(value):
try:
return 2 * value
except TypeError:
return value
@e
def quadro_value(value):
try:
return 4 * value
except TypeError:
return value
@e
def half_value(value):
try:
return value / 2
except TypeError:
return value
With the assignments in the debbuger window:
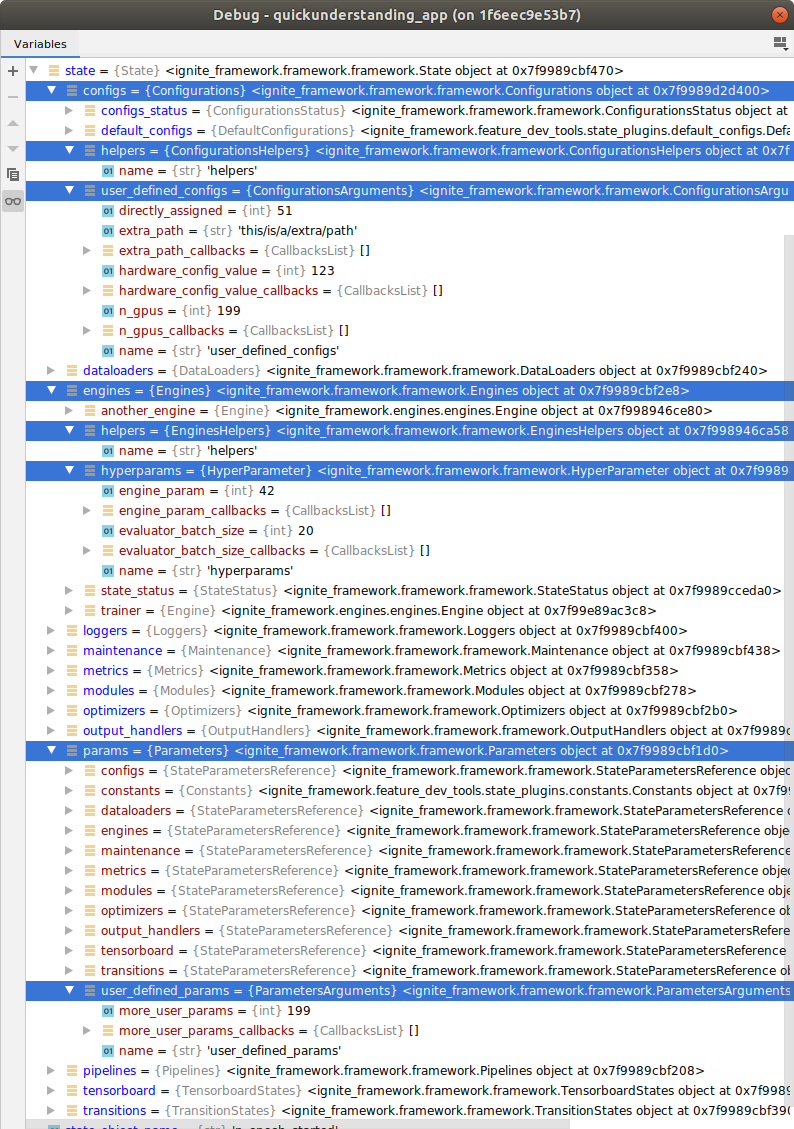
Now, which of these features will establish themselves in the daily workflow is not sure so far and it’s for sure questionable if attaching helper functions to state is useful… time will show… maybe after some time spent with another coffee!
Note
Functions may not list in some IDE debuggers
Some debuggers only have a variable debugger window not listing functions, so your helpers containers may appear empty. You can list your state functions with:
>>> state.engines.helpers.get_bso_names()
['max_process', 'double_value', 'quadro_value', 'half_value']
Automatic categorization¶
In complicated use cases many tarnsitions may be instantiated and at some point you forget what was already instantiated, where it was instantiated and how you named it. Therefore, besides the user parameters and functions, also any state object container (bso container) is automatically categorized without any extra code, even with less code as you do not have to assign the new bso container to a variable. Compare the (again random) code snippet (this time from automatic_metric_chart_creation.py) with the resulting output in the debugger state.
You will notice that the the output handlers require no naming at all (optional) and the resulting metric names in the debugger state.metrics.* differ from the provided metric_name argument by a prefix describing the preceding dataflow path of the metric. The names may appear longish but with a closer look they are very helpful. These naming assistance and auto-naming bso containers are part of the below paragraphs.
## AUTOMATIC CATEGORIZATION ##
from ignite_framework.output_handlers import OutputHandler, ScalarsChartOutputHandler
from ignite_framework.metrics import AverageOutput, OutputMetric, RunningAverage
Engine(name='evaluator',
process=state.max_process,
engine_run_started_ref=state.trainer.n_iteration_completed_every_100_ref)
OutputHandler(input_refs=state.trainer.output_ref,
transform_input_func=double_value)
# Note: `state.get(name)` is just a nicer call for `getattr(state, name)`, also works for state containers
AverageOutput(metric_name='reg_average_loss', input_ref=state.trainer_double_value.output_ref,
started_ref=state.trainer.n_iteration_completed_every_100_ref,
completed_ref=state.trainer.n_iteration_completed_every_100_ref)
OutputHandler(input_refs=state.trainer_double_value_reg_average_loss.output_ref,
transform_input_func=half_value)
ScalarsChartOutputHandler(input_refs=state.trainer_double_value_reg_average_loss.output_ref)
RunningAverage(metric_name='double_lc_running_loss',
input_ref=state.trainer_double_value.output_ref)
OutputMetric(metric_name='reg_normal_loss',
input_ref=state.trainer_double_value.output_ref)
The debugger probably gives a better overview than the implementing code:
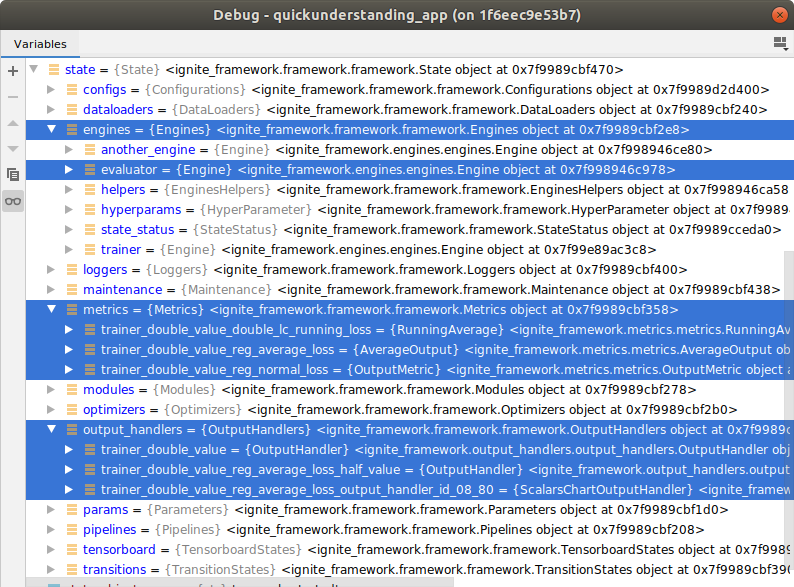
PyTorch class instance integration¶
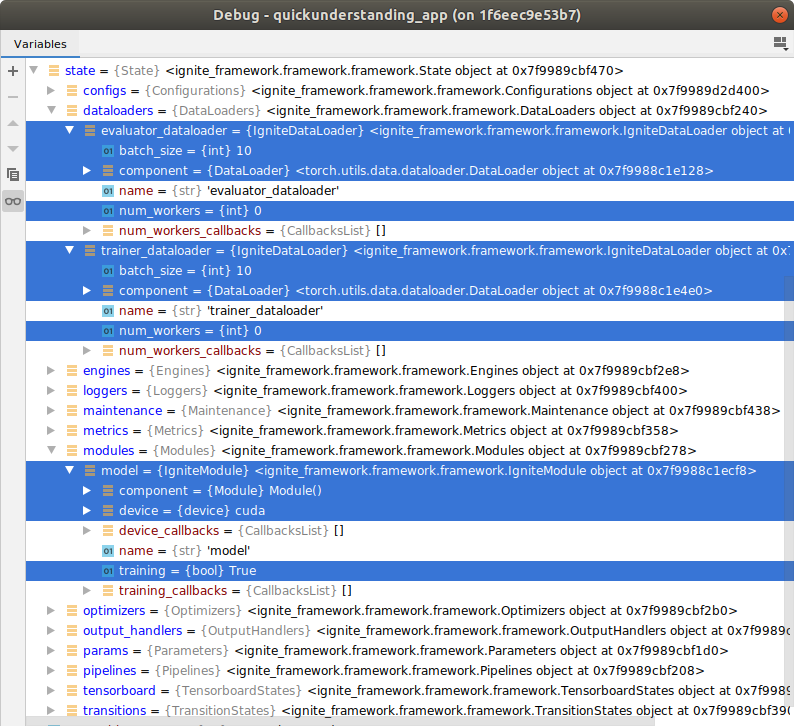
PyTorch class instances such as a intsance of DataLoader, Module, Optimizer, can be assigned to the appropriate state component containers such as respectively state.dataloaders, state.modules, state.optimizers and will be integrated as IgniteDataLoader, IgniteModule, IgniteOptimizer, which are all of type MetaStateComponents. These Ignite*-classes are created (created NOT instantiated) at runtime and then of course instantiated. The state components are integrated as follows:
- The Pytorch instance is assigned unchanged as attribute
componentto the state component instance, e.g.DataLoader()would be found instate.dataloaders.trainer_dataloader.component - Any command on the state component will be forwarded to the PyTorch class instance, unless it is meant for the state component (seamless integration)
- Pre/User-defined parameter of each subclass (all mro-classes) of the PyTorch instance are integrated as state objects directly assigned to the state compoennt (e.g.
state.dataloaders.trainer_dataloader.batch_sizeornum_workers).
Assigning a integrated PyTorch class instance is straight forward:
## EXTERNAL CLASS INTEGRATION ##
# Initiate a (random sample) dataloader
from torch.utils.data.dataloader import DataLoader
from random import randint
state.dataloaders.trainer_dataloader = \
DataLoader(dataset=[randint(0, 999) for i in range(10000)],
batch_size=10)
# For adding multiple components, or bsos
with state.dataloaders as d:
d.evaluator_dataloader = \
DataLoader(dataset=[randint(0, 99) for i in range(10)],
batch_size=10)
print(state.dataloaders.trainer_dataloader.component.dataset == state.trainer_dataloader.dataset)
try:
state.dataloaders.model = torch.nn.Module()
except Exception as e:
print(e)
# Alternatively for single components
state.modules.model = torch.nn.Module()
Integrating a subclass of PyTorch or a totally new class in the framework works more or less on the fly. That’s way it’s rather a application feature than a feature-dev tool or framework-dev tool:
## NEW CLASS INTEGRATION ##
from ignite_framework.feature_dev_tools.state_objects import StateParameter
# Define a new subclass of `Module`
class UserModule(torch.nn.Module):
def __init__(self):
self._modules = {}
self._parameters = {}
self._buffers = {}
user_module_param = 24
# Define which parameter should be integrated additinally
integrated_attrs = {'user_module_param': (StateParameter, 11, '', '')}
# Integrate
state.modules.integrate_new_state_component_class(component_class=UserModule,
integrated_attrs_args_dict=integrated_attrs)
# Assign new subclass
state.modules.a_user_module = UserModule()
In the debugger you find the state.modules.a_user_module with the state parameter user_module_param:

Naming assistance¶
State object containers must have unique names. This makes sence for the user and the framework architecture also builds on unique state object container names. For example you can NOT create a engine state.engines.trainer and name its dataloader state.dataloaders.trainer. In contrast state objects can have identical names, e.g. when multiple engines are created, all have the same n_iteration_started/completed etc..
The framework assists the user by raising an error when trying to use the same state object container name twice:
FrameworkNameError: The transition name `a_user_module` may not be used, because e.g. it already names another object in state. ...
The framework also automatically avoids identical names by adding prefixes to the user provided names, e.g. for metrics and output handlers. The user can identify the bso container’s naming assistance behaviour depending on the argument name during intialization:
- The argument name
namein__init__means no additional prefix in the state object container name, - whereas any
*_namein__init__(e.g.output_handler_name,metric_name) stands for assisted name with prefix addition.
Please find example code in the next paragraph.
Automatic naming¶
The framework supports a fully automated reasonable naming system. The only bso containers that must be named manually are:
- state components
- engines
- metrics (assisted naming, see above)
- recommended: transform functions of output handlers, but nor required
So automatically named are:
- output handlers: automated and assisted
- metrics: only assisted
- chart container: automated and manual
- chart itself:
- chart section name: automated (engine names displayed in charts of the section)
- chart name: automated and manual (metric name or accumulated mectrics name)
- graph names: automated or manual (metric container name for each graph)
- (some) transitions: automated and manual
- pipelines: automated and manual
BUT: Any automation is optional, everything can be set manually. This is often important for individual use cases.
When you look at the code example below realized the difference to the automatic categorization code example . This example shows how you can easily build up a input-output feature chain having the framework doing the naming work in the background but without having to bother about the created names yourself.
## NAME ASSISTANCE & AUTOMATIC NAMING ##
# Here the assisted/automatic generated name is assigned to a variable
# to use it for defining the input of the successive feature
t_oh = OutputHandler(input_refs=state.trainer.output_ref,
transform_input_func=quadro_value).name
t_oh_m = RunningAverage(metric_name='quadro_lc_running_loss',
input_ref=state.get(t_oh).output_ref).name
ScalarsChartOutputHandler(input_refs=state.get(t_oh_m).output_ref,
transform_input_func=double_value).name
You fetch the created name with the .name at the end of the feature and use it for the parametrized input setting state.get(<feature_name>) in the successive feature. Recognizing the implemented bso-container later in the debugger is effortless thanks to the simple, resonable naming:
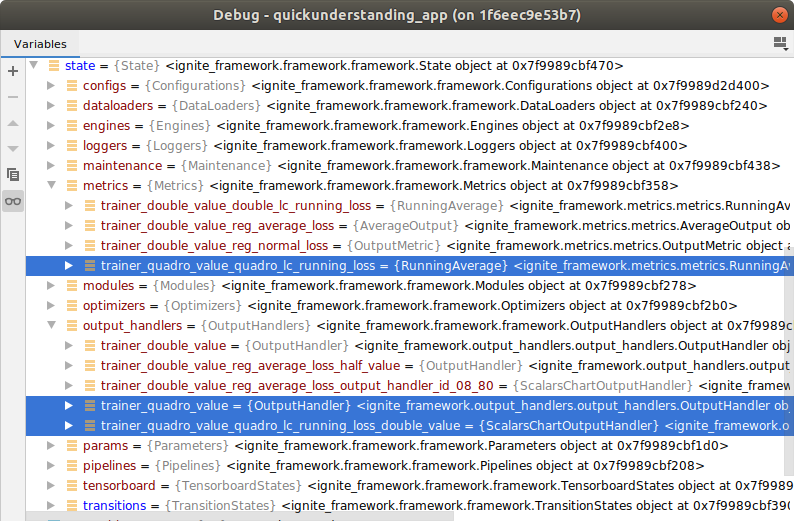
State Container Status¶
state offers from the very first beginning already many times more callbacks (events) than the current Ignite (~9) which is expected as they are integrated in each state object (note: in almost each). The most standardized ones are those of the state containers state.engines.state_status, state.configs.configs_status and state.maintenance.maintenance_status and , namely ``*_init_started, *_init_completed, *_run_started and *_run_completed. Each of the state container runs though all 4 of them changine their boolean value form False to True & triggering their callbacks. These callbacks serve the user as default callbacks (events) to individualize her/his bso containers and applications.
Everything starts with the state.engines.state_status state objects (which are set in state.run()) and the others are appended to the callbacks, see below in the watch list of the debugger. Features and transitions in each state container can be appended to those callbacks respectively:
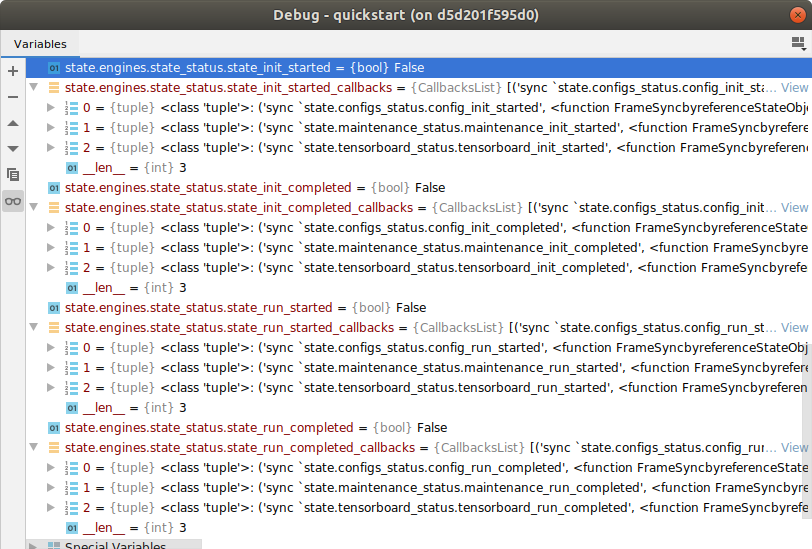
The status of the other state containers are found for example in state.configs.configs_status or state.tensorboard.tensorboard_status.ncremental accumulated from each subclasses so when integrating a new subclass only the new parameters need to be integrated.
Plugin tools¶
The state architecture promotes the enhancement and individualization of itself with plugins. This is part of the Quickunderstanding Feature Dev. A plugin integrated in the default state is the data flow graph analysis tools in state.maintenance.dataflow nicely demonstated in automatic_metric_chart_creation.py:
# Note: Here the tool functions are stored in `StateFunction`s, a type of state object
>>> state.maintenance.dataflow.get_bso_names()
['get_graphs_in_state',
'get_paths_in_state_formatted_as_graphs',
'get_graphs_including_bso_ctr',
'get_successive_graph_of_bso_ctr',
'get_bso_ctr_names_in_paths_formatted_as_graph',
'get_paths_in_graph',
'get_paths_in_state',
'get_paths_including_bso_ctr',
'get_preceding_paths_of_bso_ctr',
'get_successive_paths_of_bso_ctr',
'get_engine_names_in_state',
'get_metric_names_of_engine',
'get_engine_names_in_paths_including_bso_ctr',
'get_metric_names_in_paths_including_bso_ctr',
'get_engine_names_in_paths',
'get_metric_names_in_paths',
'get_bso_ctr_names_of_type_in_paths_including_bso_ctr',
'get_bso_ctr_names_of_type_in_paths',
'get_bso_ctr_types_in_preceding_paths',
'get_bso_ctr_types_in_paths',
'get_bso_ctr_instances_in_paths',
'get_successors_of_bso_ctr',
'get_predecessors_of_bso_ctr']
# Try in a finish training script the command:
state.get_graphs_in_state()
It gives you full information about the datafow from the dataloader through all transitions to the file/tensorboard logger or chart. You get the perfect overview how the bso containers are referencing from each other. The implementation of the data flow graph visualization would be a next tool. Other tool would be the a time sequential callback analysis tool to complement the overview of the training loops.
Another already existing plugin is state.maintenance.state_timer.
Pipelines and State Object Container Compositions¶
Pipelines and state object container composition are high-leve APIs that orchestrate multiple (low-level) bso containers, e.g. dataloaders, engines, metrics, output handlers, charts etc.. Currently there are 2 pipelines and 2 state object container compositions implemented, namely SupervisedTrainer, SupervisedEvaluator (roughly implemented) and EngineMetricsCharts, EnginesMetricsComparisonCharts. The difference between a pipeline and a composition is that the pipeline manages different kinds of bso containers in different state containers and therefore is assigned to state.pipelines whereas the composition only orchestrates bso containers of one state container and therefore is assigned to that state container.
Most important for high-level APIs is only to manage existing `bso container` (or other high-level APIs) but never provide own features itself.
Nice pipelines and compositions examples are mnist.mnist_with_tensorboard_logger_and_high_level_apis.py and its identical implementation with low-level bso containers mnist.mnist_with_tensorboard_logger_and_low_level_apis.py and for compositions only have a look at automatic_metric_chart_creation.py.
Exceptions¶
Framework for feature development and application the exceptions are categorized into Framework*Errors and Feature*Errors serving the feature developer to give a hint if framework code may be required for debugging.
